
RUBY
[CRIME] 4. Pandas Pivot Table 본문
서울시 범죄 현황 데이터 분석 프로젝트
4. Pandas Pivot Table
index, columns, values, aggfunc
1. 간단한 판매 현황표를 가져와본다.

df = pd.read_excel("../data/02. sales-funnel.xlsx")
df.head()
2. Name 컬럼을 인덱스로 설정하고 재정렬해보려한다.
# pd.pivot_table(df, index="Name")

df.pivot_table(index="Name")C:\Users\JIEUN\AppData\Local\Temp\ipykernel_17280\4182054485.py:1: FutureWarning: pivot_table dropped a column because it failed to aggregate. This behavior is deprecated and will raise in a future version of pandas. Select only the columns that can be aggregated.
df.pivot_table(index="Name")경고창이 뜬다.

import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
가볍게 없애준다.

df.pivot_table(index="Name")재출력하니 경고창이 나오지 않고 잘 출력된다.
3. 멀티인덱스 : index를 여러개 지정할 수 있다.

df.pivot_table(index=["Name", "Rep", "Manager"])
df.pivot_table(index=["Manager", "Rep"])
4.
- values를 지정할 수 있다.

pd.pivot_table(df, index=["Manager", "Rep"], values=["Price"])
5.
- values에 함수를 적용할 수 있다.
- 디폴트는 평균
- 합산 등의 다른 함수를 적용할 때는 aggfunc 옵션을 지정

pd.pivot_table(df, index=["Manager", "Rep"], values=["Price"], aggfunc=np.sum)
6.
갯수도 적용(len)
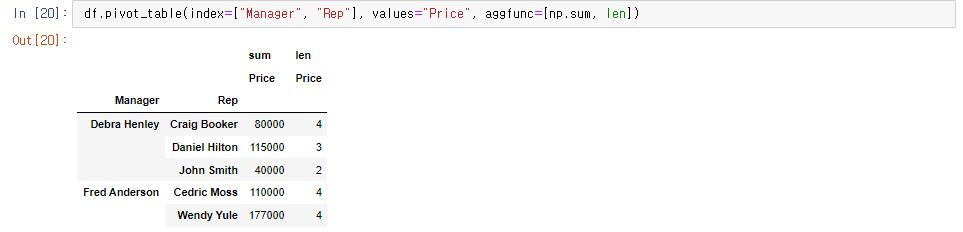
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=[np.sum, len])
7.
분류를 지정(columns)

df.head()
8.
Product를 컬럼으로 지정
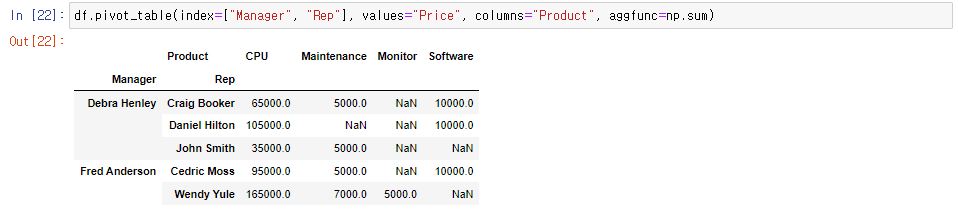
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)
9.
NaN에 대한 처리를 지정 fill_value

df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum, fill_value=0)
10.
2개 이상 index, values 설정

df.pivot_table(index=["Manager", "Rep", "Product"], values=["Price", "Quantity"], aggfunc=np.sum, fill_value=0)
11.
aggfunc 2개 이상 설정
총계(All) 추가, 합계를 지정할 수 있다.

df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True)
12.
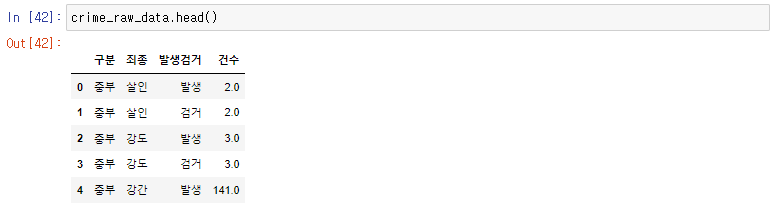
crime_raw_data.head()
13.
- 경찰서 이름을 index로 하도록 정리하자
- defaul가 평균(mean)이므로 사건의 합을 기록하기 위해 aggfunc 옵션에 sum을 사용하는 것에 주의한다.

crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index="구분",
columns=["죄종", "발생검거"],
aggfunc=[np.sum])
crime_station.head()
14.
- Multiindex. 깔끔하게 정리된다.
- 그러나 이렇게 정리된 데이터의 경우 column이 multi로 잡힌다.
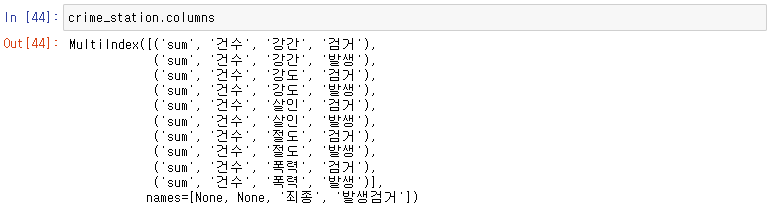
crime_station.columns
15.
- Multi Columns Index
- pivot_table을 적용하면 column이나 index가 다중으로 잡힌다.

crime_station["sum", "건수", "강도", "검거"][:5]
16.
- 다중 컬럼에서 특정 컬럼을 제거한다.

crime_station.columns = crime_station.columns.droplevel([0, 1])
crime_station.columns
17.
crime_station.head()
18.
- 현재 index는 경찰서 이름으로 되어있다.
- 경찰서 이름으로 구이름을 알아내야 한다.

crime_station.index
'데이터 분석 > EDA_웹크롤링_파이썬프로그래밍' 카테고리의 다른 글
| [CRIME] 6. Google Maps API설치하기 (0) | 2023.02.03 |
|---|---|
| [CRIME] 5. Python 모듈 설치하기(pip, conda) (0) | 2023.02.03 |
| [CRIME] 3. 데이터 확인하고 초기 정리하기 (0) | 2023.02.03 |
| [CRIME] 2. 데이터 얻기 (0) | 2023.02.03 |
| [CRIME] 1. 목표 (0) | 2023.02.02 |



