
RUBY
[CCTV] 3.Pandas로 데이터 읽기(1) 본문
서울시 CCTV 분석하기 프로젝트
3.Pandas로 데이터 읽기(1)
Pandas
Pandas는 데이터 조작 및 분석을 위한 Python 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리이다. 숫자 테이블과 시계열을 조작하기 위한 데이터 구조와 연산을 제공하며, 무료 소프트웨어 New BSD 라이센스이다. pandas란 이름은 한 개인에 대해 여러 기간동안 관찰을 한다는 데이터 세트에 대한 계량 경제학 용어인 "패널 데이터"라는 용어에서 파생되었다. 또한 "Python 데이터 분석"이라는 문구 자체에서 따온 것이기도 하다. Wes McKinney 는2007년부터 2010년까지 연구원으로 있을 때 AQR Capital에서 pandas를 만들기 시작했다.
- 통합 인덱싱으로 데이터 조작을 위한 Data Frame 개체
- 메모리 내 데이터 구조 와 다른 파일 형식 간에 데이터를 읽고 쓰는 도구
- 데이터 정렬 및 누락된 데이터의 통합 처리
- 데이터 세트의 재구성 및 피벗
- 레이블 기반 슬라이싱, 멋진 인덱싱 및 대규모 데이터 세트의 하위 집합
- 데이터 구조 열 삽입 및 삭제
- 데이터 세트에 대한 분할-적용-결합 작업을 허용하는 엔진별로 그룹화
- 데이터 세트 병합 및 결합
- 저차원 데이터 구조에서 고차원 데이터로 작업하기 위한 계층적 축 인덱싱
- 시계열 기능: 날짜 범위 생성 및 빈도 변환, 이동 창 통계, 이동 창 선형 회귀, 날짜 이동 및 지연
- 데이터 필터링을 제공
- 라이브러리는 Python 또는 C로 작성된 코드를 사용하여 성능에 대해 최적화가 되어 있다.
Pandas는 주로 데이터 분석에 사용된다. Pandas를 사용하면 쉼표로 구분된 값, JSON, SQL 및 Microsoft Excel 과 같은 다양한 파일 형식에서 데이터를 가져올 수 있다. 병합 등의 각종 데이터 처리 동작을 허용, 재편, 선택 뿐만 아니라 청소 데이터 및 데이터 승강이 가능하다.
1. Anaconda Prompt를 실행한다.

2. 콘다에서 전에 만들어 둔 ds_study 커널을 실행해준다.

conda activate ds_study
→ ds_study 실행
cd Documents/ds_study
→ 작업 폴더로 이동하기
jupyter notebook
→ jupyter notebook 실행
3. 주피터가 실행되었다.

4.source_code 폴더로 이동하여 작업을 시작해보자

5. 어.. 만들어둔 ds_study 커널이 보이지 않는다.

5. 1)Anaconda Prompt로 돌아오자
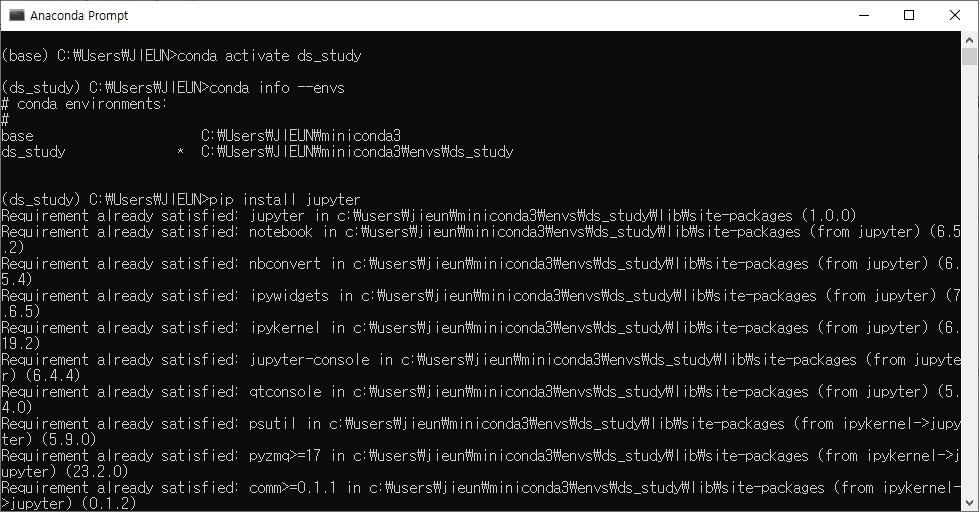
conda activate ds_study
→ ds_study 실행
conda info --envs
→ 현재 선택 된 환경을 확인한다.
pip install jupyter
→ 현재 가상환경에 jupyter을 설치한다.

conda install ipykernel
→ 가상 환경 커널 추가를 도와주는 패키지파일 설치하기

python -m ipykernel install --user --name 가상환경이름 --display-name 가상환경이름
→ 커널을 생성하는 명령어, 가상환경은 연결해야 될 가상환경명칭과 커널명은 주피터에서 보여질 명칭이라고 생각하면 된다.
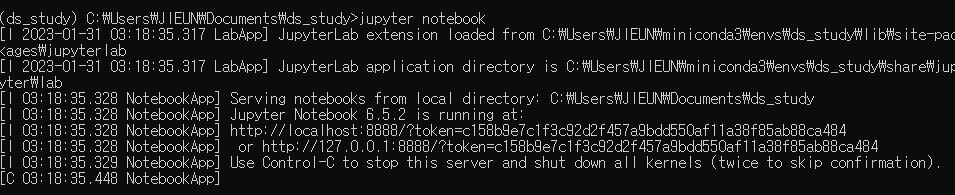
jupyter notebook
→ 주피터 노트북을 실행한다.

성공..
6. New - ds_study 클릭

7. 제목을 바꿔보자
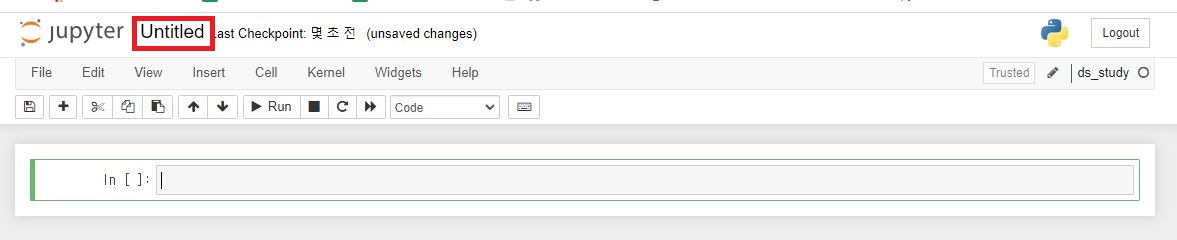
8. Rename 설정

9.
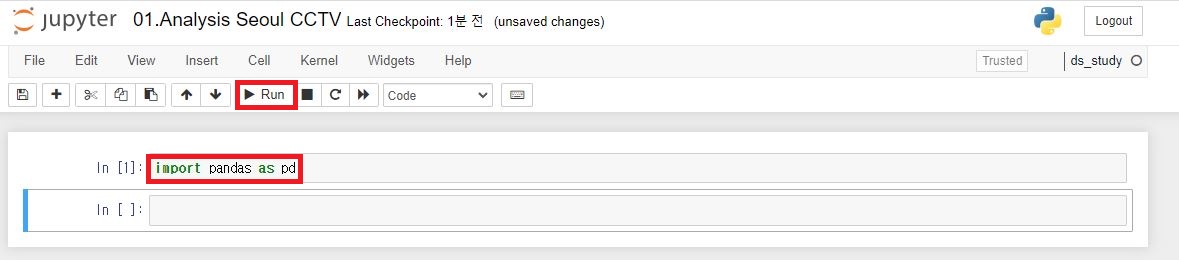
import pandas as pd입력 후 Run
10. pandas가 설치되지 않았다고 나올 시
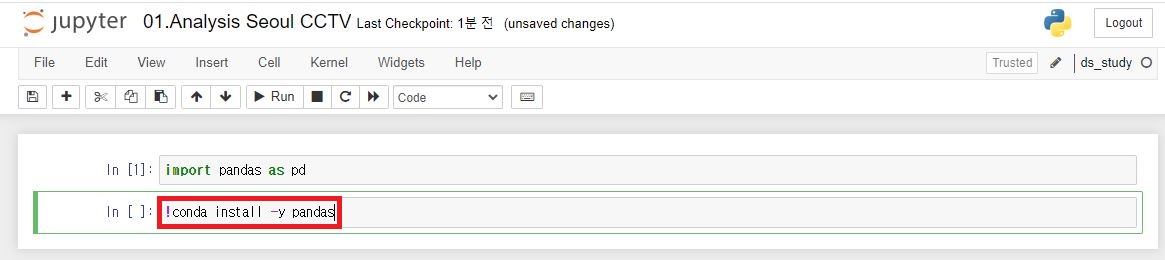
!conda install -y pandas를 입력하여 실행해준다.
11. 데이터를 불러오자

CCTV_Seoul = pd.read_csv("../data/01.Seoul_CCTV.csv")tab을 누르면 경로에 있는 폴더나 파일들이 나온다..
12. UnicodeDecodeError Traceback (most recent call last)

인코딩이 깨진다.
간단하게 오류를 고쳐보자.
13.

CCTV_Seoul = pd.read_csv("../data/01.Seoul_CCTV.csv", encoding='cp949')encoding='cp949'를 추가 입력해준다.
윈도우는 한글 인코딩시 cp949 방식을 쓴다. 윈도우에서 엑셀로 파일을 열고 저장을 하면 cp949방식으로 저장을 하기 때문에 encoding='cp949'로 설정해주면 깨지지 않는다.
14. 데이터가 잘 불러와졌나 확인해보자

CCTV_Seoul.head()데이터 상단 5줄을 불러온다.
15.

CCTV_Seoul.head(3)데이터 상단 3줄을 불러온다.
16.

CCTV_Seoul.tail()데이터 하단 5줄을 불러온다.
17.

CCTV_Seoul.columnscolumns명을 불러온다.
18.

CCTV_Seoul.columns[0][0]번째에 있는 컬럼명을 불러온다.
19.
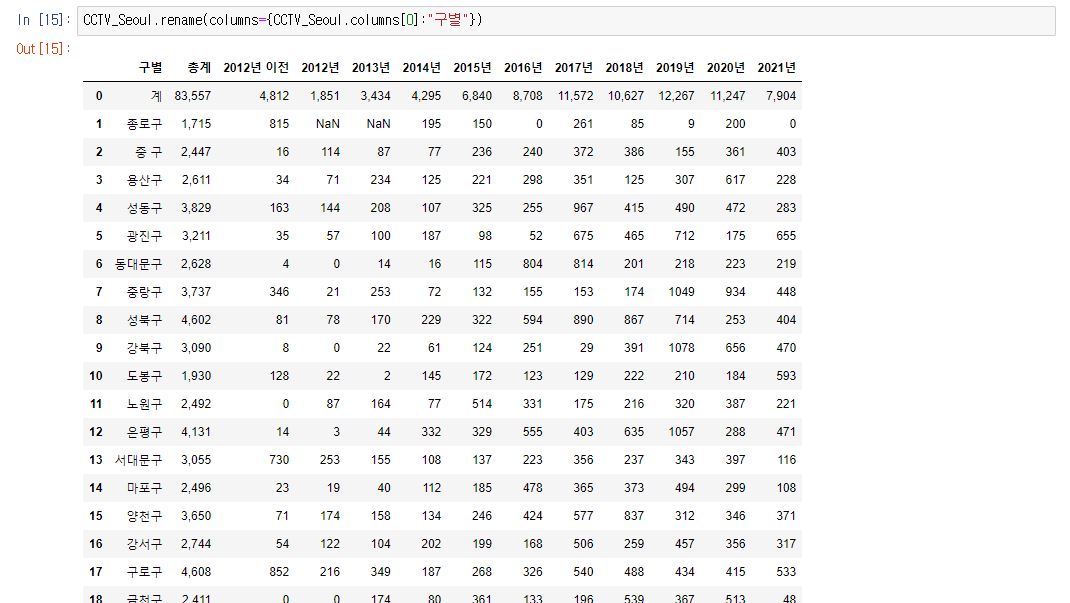
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]:"구별"})[0]번째에 있는 컬럼명을 "구별"로 바꾸어 출력한다.
20.
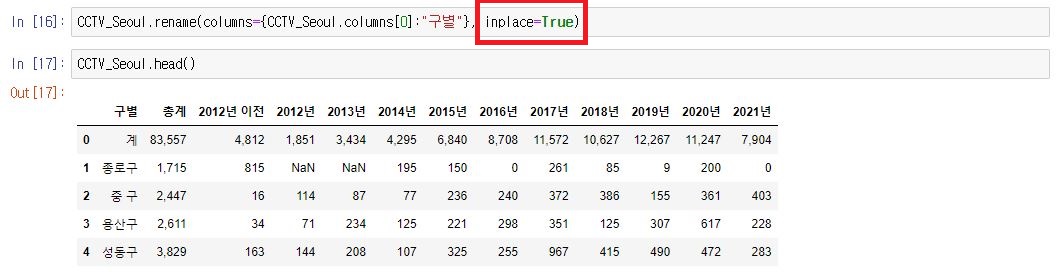
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]:"구별"}, inplace=True)[0]번째에 있는 컬럼명을 "구별"로 바꾸어 저장 및 출력한다.
21.
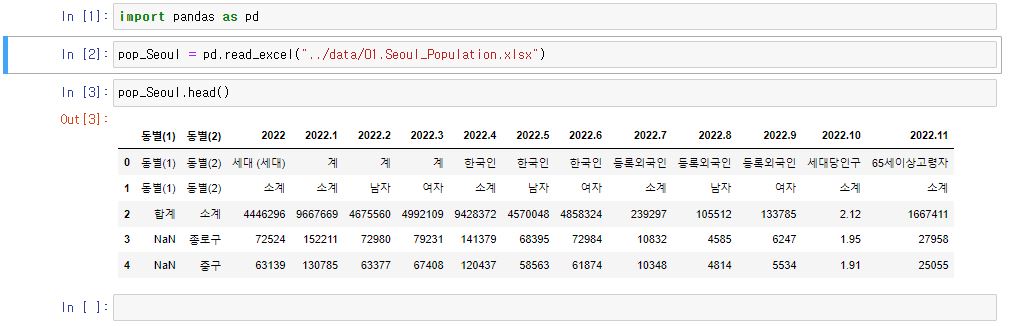
import pandas as pdpop_Seoul = pd.read_excel("../data/01.Seoul_Population.xlsx")pop_Seoul.head()엑셀 파일을 열어본다. 행이 지저분하게 출력되어있다.
22.

엑셀 원본을 확인해보니 원래 이렇게 되어있다.
23.

pop_Seoul = pd.read_excel("../data/01.Seoul_Population.xlsx", header=2, usecols="B, D, G, J, N")
pop_Seoul.head()* 자료 읽기를 시작할 행(header)를 지정
* 읽어올 엑셀의 컬럼(usecols)을 지정해본다.
24.

pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "합계",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자",
},
inplace=True,
)
pop_Seoul.head()컬럼 이름을 바꿔보자
'데이터 분석 > EDA_웹크롤링_파이썬프로그래밍' 카테고리의 다른 글
| [CCTV] 3.Pandas로 데이터 읽기(3) (0) | 2023.02.01 |
|---|---|
| [CCTV] 3.Pandas로 데이터 읽기(2) (1) | 2023.02.01 |
| [CCTV] 2.데이터 확보 (0) | 2023.01.31 |
| [CCTV] 1. 목표 (0) | 2023.01.31 |
| Google Colabotatory 사용하기, 한글 설정하기, Markdown사용, google drive 연동 (0) | 2023.01.29 |


