
RUBY
[CRIME] 10. 범죄 데이터 정렬을 위한 데이터 정리 본문
서울시 범죄 현황 데이터 분석 프로젝트
10. 범죄 데이터 정렬을 위한 데이터 정리
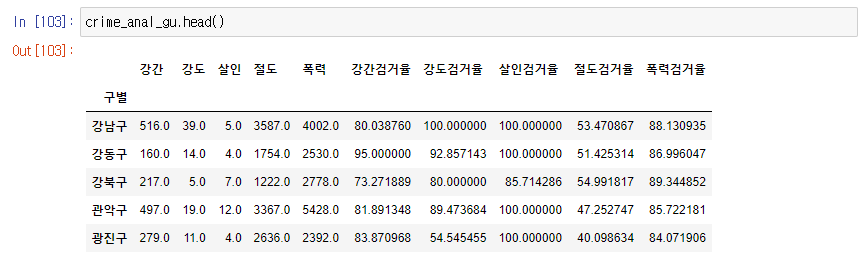
crime_anal_gu.head()
1.
- 정규화
- 본래의 DataFrame은 두고, 정규화 된 데이터를 따로 만든다.
- 최고값을 1로 두고, 최소값을 0으로둔다.

crime_anal_gu["강도"] / crime_anal_gu["강도"].max()
2. 데이터 정리하기
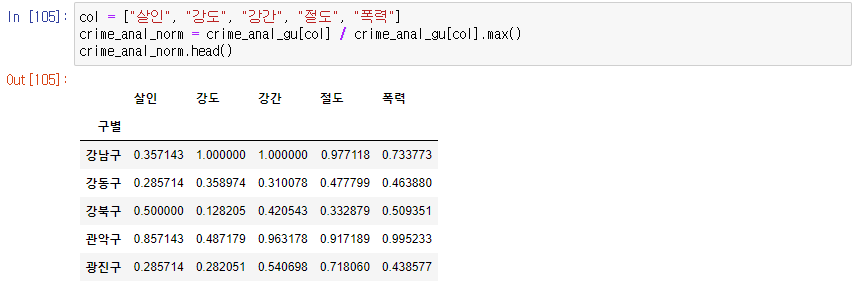
col = ["살인", "강도", "강간", "절도", "폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norm.head()
3. 검거율을 추가하자

col2 = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm[col2] = crime_anal_gu[col2]
crime_anal_norm.head()
4.
- 데이터 정리를 완료했다.
- 구별 CCTV자료에서 인구수와 CCTV수를 가져오자
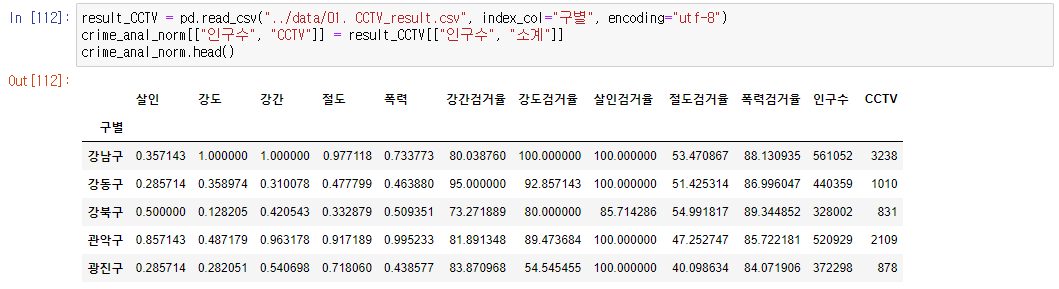
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv", index_col="구별", encoding="utf-8")
crime_anal_norm[["인구수", "CCTV"]] = result_CCTV[["인구수", "소계"]]
crime_anal_norm.head()
5.
- 정규화 된 범죄 발생 건수 전체의 평균을 구해서 범죄의 대표값으로 사용하자

col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()
6.
- 검거율의 평균을 구해서 검거 컬럼의 대표값으로 사용하자
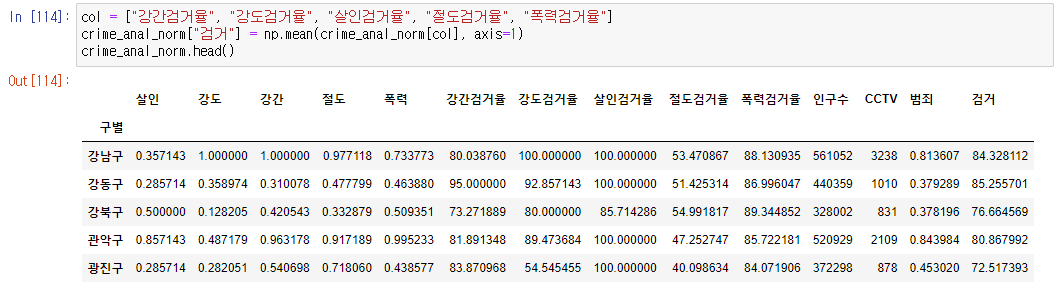
col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()
7. 전체데이터 살펴보기
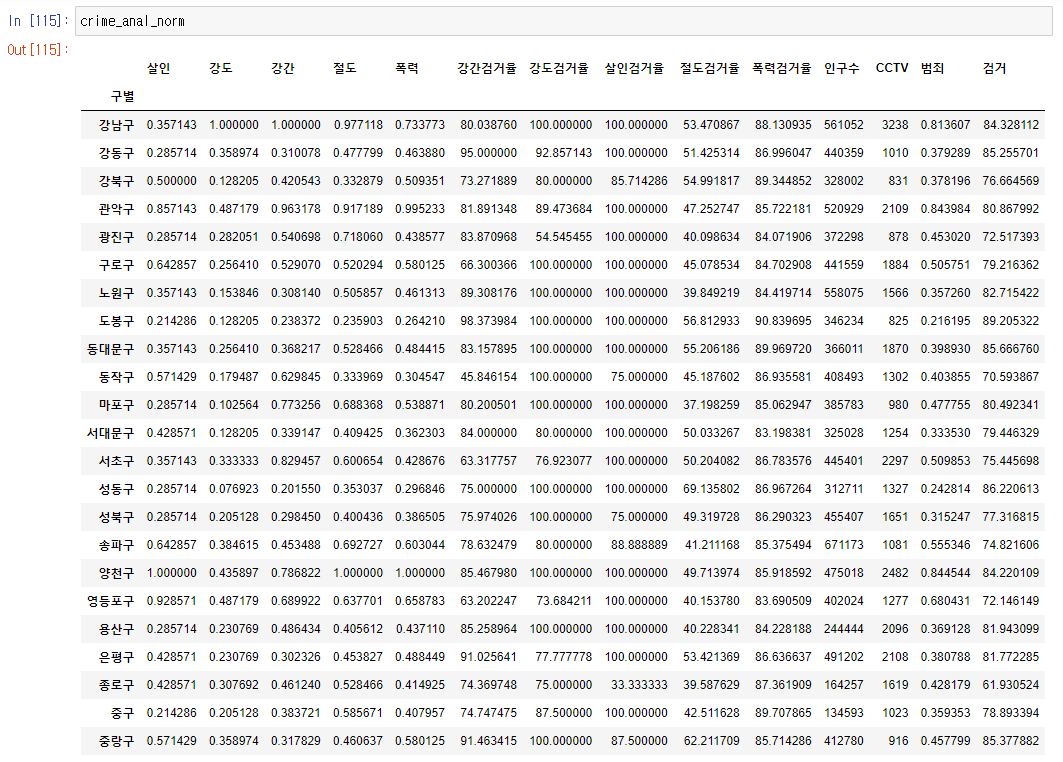
crime_anal_norm'데이터 분석 > EDA_웹크롤링_파이썬프로그래밍' 카테고리의 다른 글
| [CRIME] 12. 서울시 범죄현황 데이터 시각화(pair plot, heat map) (0) | 2023.02.03 |
|---|---|
| [CRIME] 11. seaborn (0) | 2023.02.03 |
| [CRIME] 9. 구별 데이터 얻기 (1) | 2023.02.03 |
| [CRIME] 8. Google Maps을 이용한 데이터 정리 (1) | 2023.02.03 |
| [CRIME] 7. Python의 반복문 (0) | 2023.02.03 |
'데이터 분석/EDA_웹크롤링_파이썬프로그래밍' Related Articles
more




Comments