
RUBY
[WebData][chicago] 2. 접근 태그 확인하기 본문
웹 데이터 수집하고 정리하기
시카고 맛집 데이터 분석
2. 접근 태그 확인하기
1. !pip install fake-useragent
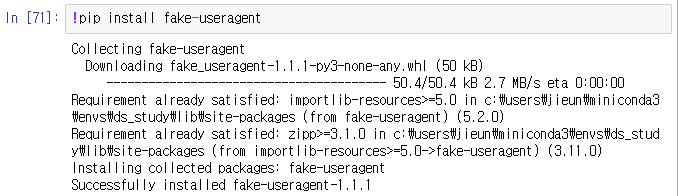
!pip install fake-useragent
2. 이대로 바로 소개 페이지를 분석하려하면,
SSL 오류가 뜬다.

더보기
---------------------------------------------------------------------------
SSLCertVerificationError Traceback (most recent call last)
File ~\miniconda3\envs\ds_study\lib\urllib\request.py:1354, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1353 try:
-> 1354 h.request(req.get_method(), req.selector, req.data, headers,
1355 encode_chunked=req.has_header('Transfer-encoding'))
1356 except OSError as err: # timeout error
File ~\miniconda3\envs\ds_study\lib\http\client.py:1256, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1255 """Send a complete request to the server."""
-> 1256 self._send_request(method, url, body, headers, encode_chunked)
File ~\miniconda3\envs\ds_study\lib\http\client.py:1302, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1301 body = _encode(body, 'body')
-> 1302 self.endheaders(body, encode_chunked=encode_chunked)
File ~\miniconda3\envs\ds_study\lib\http\client.py:1251, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1250 raise CannotSendHeader()
-> 1251 self._send_output(message_body, encode_chunked=encode_chunked)
File ~\miniconda3\envs\ds_study\lib\http\client.py:1011, in HTTPConnection._send_output(self, message_body, encode_chunked)
1010 del self._buffer[:]
-> 1011 self.send(msg)
1013 if message_body is not None:
1014
1015 # create a consistent interface to message_body
File ~\miniconda3\envs\ds_study\lib\http\client.py:951, in HTTPConnection.send(self, data)
950 if self.auto_open:
--> 951 self.connect()
952 else:
File ~\miniconda3\envs\ds_study\lib\http\client.py:1425, in HTTPSConnection.connect(self)
1423 server_hostname = self.host
-> 1425 self.sock = self._context.wrap_socket(self.sock,
1426 server_hostname=server_hostname)
File ~\miniconda3\envs\ds_study\lib\ssl.py:500, in SSLContext.wrap_socket(self, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, session)
494 def wrap_socket(self, sock, server_side=False,
495 do_handshake_on_connect=True,
496 suppress_ragged_eofs=True,
497 server_hostname=None, session=None):
498 # SSLSocket class handles server_hostname encoding before it calls
499 # ctx._wrap_socket()
--> 500 return self.sslsocket_class._create(
501 sock=sock,
502 server_side=server_side,
503 do_handshake_on_connect=do_handshake_on_connect,
504 suppress_ragged_eofs=suppress_ragged_eofs,
505 server_hostname=server_hostname,
506 context=self,
507 session=session
508 )
File ~\miniconda3\envs\ds_study\lib\ssl.py:1040, in SSLSocket._create(cls, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, context, session)
1039 raise ValueError("do_handshake_on_connect should not be specified for non-blocking sockets")
-> 1040 self.do_handshake()
1041 except (OSError, ValueError):
File ~\miniconda3\envs\ds_study\lib\ssl.py:1309, in SSLSocket.do_handshake(self, block)
1308 self.settimeout(None)
-> 1309 self._sslobj.do_handshake()
1310 finally:
SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1131)
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
Cell In[2], line 10
8 ua = UserAgent()
9 req = Request(url, headers={"user-agent": ua.ie})
---> 10 html = urlopen(req)
11 soup = BeautifulSoup(html, "html.parser")
12 print(soup.prettify())
File ~\miniconda3\envs\ds_study\lib\urllib\request.py:222, in urlopen(url, data, timeout, cafile, capath, cadefault, context)
220 else:
221 opener = _opener
--> 222 return opener.open(url, data, timeout)
File ~\miniconda3\envs\ds_study\lib\urllib\request.py:525, in OpenerDirector.open(self, fullurl, data, timeout)
522 req = meth(req)
524 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 525 response = self._open(req, data)
527 # post-process response
528 meth_name = protocol+"_response"
File ~\miniconda3\envs\ds_study\lib\urllib\request.py:542, in OpenerDirector._open(self, req, data)
539 return result
541 protocol = req.type
--> 542 result = self._call_chain(self.handle_open, protocol, protocol +
543 '_open', req)
544 if result:
545 return result
File ~\miniconda3\envs\ds_study\lib\urllib\request.py:502, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)
500 for handler in handlers:
501 func = getattr(handler, meth_name)
--> 502 result = func(*args)
503 if result is not None:
504 return result
File ~\miniconda3\envs\ds_study\lib\urllib\request.py:1397, in HTTPSHandler.https_open(self, req)
1396 def https_open(self, req):
-> 1397 return self.do_open(http.client.HTTPSConnection, req,
1398 context=self._context, check_hostname=self._check_hostname)
File ~\miniconda3\envs\ds_study\lib\urllib\request.py:1357, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1354 h.request(req.get_method(), req.selector, req.data, headers,
1355 encode_chunked=req.has_header('Transfer-encoding'))
1356 except OSError as err: # timeout error
-> 1357 raise URLError(err)
1358 r = h.getresponse()
1359 except:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1131)>
3. 임시로 이 코드를 추가해주면 오류가 해결된다.

import ssl
ssl._create_default_https_context = ssl._create_unverified_context
4. 정상 출력 확인하기

from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/"
url = url_base + url_sub
ua = UserAgent()
req = Request(url, headers={"user-agent": ua.ie})
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
5. div의 sammy 클래스가 눈에 보인다.
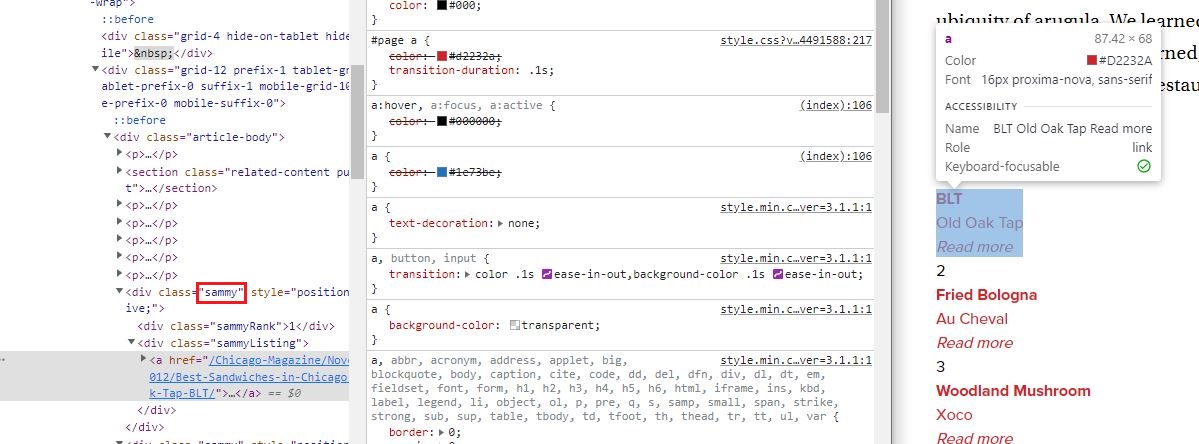
6. div의 sammy 클래스를 읽어보자
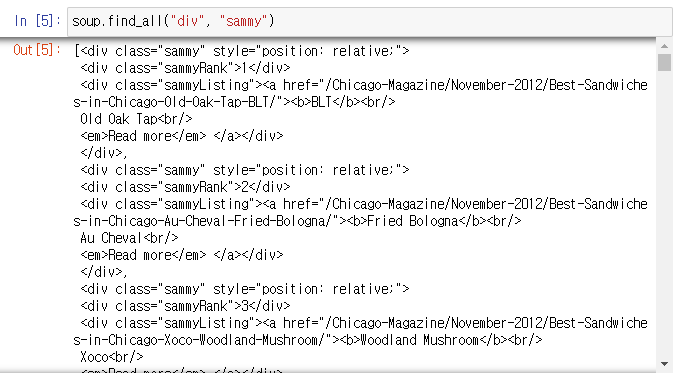
soup.find_all("div", "sammy")
7. 50개가 제대로 들어온 것을 확인한다.

len(soup.find_all("div", "sammy"))
8.
- 한 항목만 살펴보자
- 원하는 정보 중 랭킹, 가게이름, 메뉴가 눈에 띈다.

print(soup.find_all("div", "sammy")[0])
9. type을 확인해보니 bs4.element.Tag이다 find 명령을 사용할 수 있다.

tmp_one= soup.find_all("div", "sammy")[0]
type(tmp_one)
10. 랭킹 데이터를 확보한다.

tmp_one.find(class_="sammyRank").get_text()
11. 가게 이름과 메뉴 데이터가 한 번에 있다.

tmp_one.find("div", {"class":"sammyListing"}).get_text()
12. 연결되는 홈페이지 주소를 살펴보니 "상대경로"이다.

tmp_one.find("a")["href"]
13. 가게 이름과 메뉴는 re 모듈의 split으로 쉽게 구분할 수 있다.

import re
tmp_string = tmp_one.find(class_="sammyListing").get_text()
re.split(("\n|\r\n"), tmp_string)
print(re.split(("\n|\r\n"), tmp_string)[0])
print(re.split(("\n|\r\n"), tmp_string)[1])참 쉽죠?..
'데이터 분석 > EDA_웹크롤링_파이썬프로그래밍' 카테고리의 다른 글
| [WebData][chicago] 4. 하위페이지 분석 (0) | 2023.02.05 |
|---|---|
| [WebData][chicago] 3. 50개 가게에 대해 정보 추출 (0) | 2023.02.05 |
| [WebData][chicago] 1. 시카고 샌드위치 맛집 소개 페이지 분석 (0) | 2023.02.05 |
| [WebData] 4. Python List 데이터형 (0) | 2023.02.05 |
| [WebData] 3. Beautiful Soup (1) | 2023.02.05 |
'데이터 분석/EDA_웹크롤링_파이썬프로그래밍' Related Articles
more




Comments