
RUBY
[WebData][chicago] 3. 50개 가게에 대해 정보 추출 본문
웹 데이터 수집하고 정리하기
시카고 맛집 데이터 분석
3. 50개 가게에 대해 정보 추출
1.
- 필요한 내용을 담을 빈 리스트를 만든다.
- 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정이다.
- div의 sammy 태그를 가져온다.soup.select(".sammy")
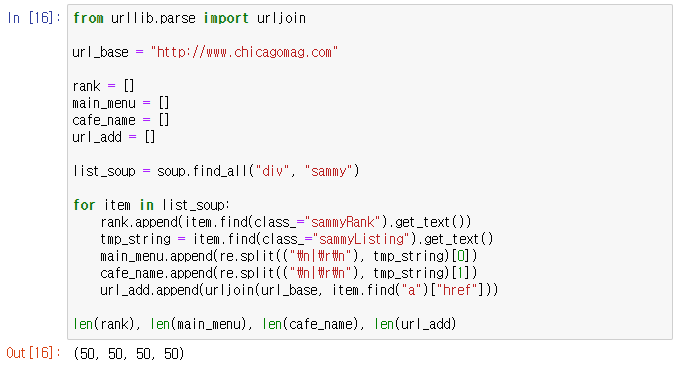
from urllib.parse import urljoin
url_base = "http://www.chicagomag.com"
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))
len(rank), len(main_menu), len(cafe_name), len(url_add)
2. 아주 잘 가져온다.
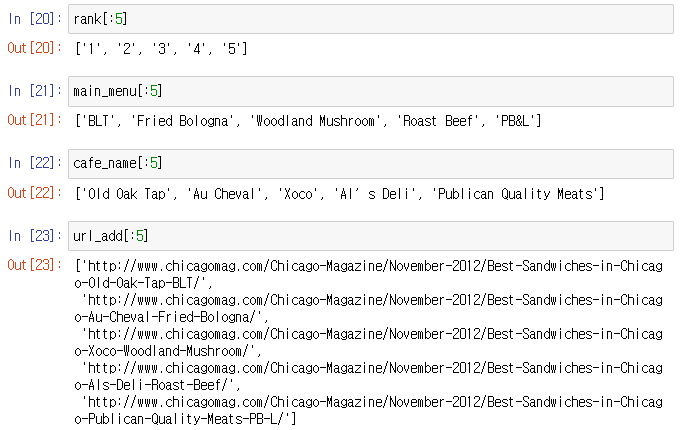
rank[:5]main_menu[:5]cafe_name[:5]url_add[:5]
3. 50개 자료에 대해 랭킹, 메뉴, 가게이름, URL까지 모두 정리한다.

import pandas as pd
data = {
"Rank": rank,
"Menu": main_menu,
"Cafe": cafe_name,
"URL": url_add,
}
df = pd.DataFrame(data)
df.tail()
4. 칼럼 순서를 변경한다.
- Rank. Cafe, Menu, URL 순서이다.
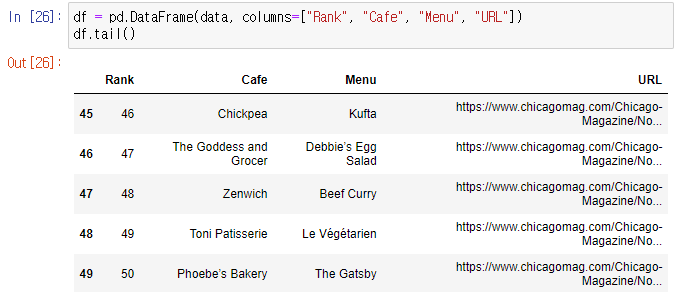
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.tail()
5. 만든 데이터를 저장하자!

df.to_csv(
"../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8"
)'데이터 분석 > EDA_웹크롤링_파이썬프로그래밍' 카테고리의 다른 글
| [WebData][chicago] 5. Regular Expression (1) | 2023.02.05 |
|---|---|
| [WebData][chicago] 4. 하위페이지 분석 (0) | 2023.02.05 |
| [WebData][chicago] 2. 접근 태그 확인하기 (0) | 2023.02.05 |
| [WebData][chicago] 1. 시카고 샌드위치 맛집 소개 페이지 분석 (0) | 2023.02.05 |
| [WebData] 4. Python List 데이터형 (0) | 2023.02.05 |
'데이터 분석/EDA_웹크롤링_파이썬프로그래밍' Related Articles
more




Comments