
RUBY
[WebData][chicago] 5. Regular Expression 본문
웹 데이터 수집하고 정리하기
시카고 맛집 데이터 분석
5. Regular Expression
Regular Expression(정규 표현식)
정규표현식의 사전적의미로는 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어이다. 주로 Programming Language나 Text Editor 등에서 문자열의 검색과 치환을 위한 용도로 쓰이고 있다. 입력한 문자열에서 특정한 조건을 표현할 경우 일반적인 조건문으로는 다소 복잡할 수도 있지만, 정규 표현식을 이용하면 매우 간단하게 표현할 수 있다. 하지만 코드가 간단한 만큼 가독성이 떨어져서 표현식을 숙지하지 않으면 이해하기 힘들다는 문제점이 있다.

1. 가격과 주소만 가져오기 위해 .,로 분리한다.

import re
re.split(".,", price_tmp)price_tmp = re.split(".,", price_tmp)[0]
price_tmp
2. 숫자로 시작하다가 꼭 . 을 만나고 그 뒤 숫자가 있을 수도 있고 아닐 수도 있다.

re.search("\$\d+\.(\d+)?", price_tmp).group()
3. 가격이 끝나는 지점의 위치를 이용해서 그 뒤는 주소로 생각한다.

tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:]
4. 방금 작성한 것을 50번 반복하면 된다^^..
- 코드의 동작 유무를 살짝 확인하기 위해 세번만 돌려보자.
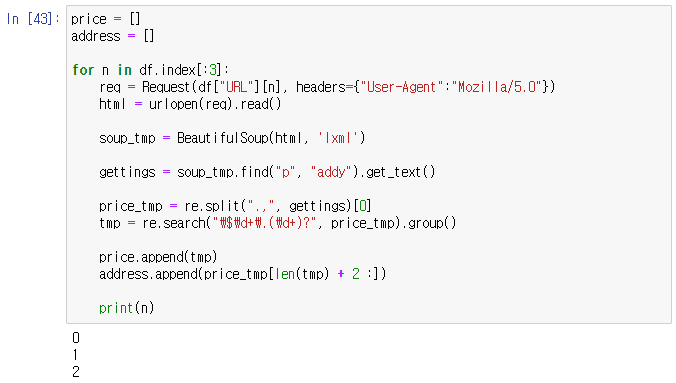
price = []
address = []
for n in df.index[:3]:
req = Request(df["URL"][n], headers={"User-Agent":"Mozilla/5.0"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'lxml')
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2 :])
print(n)이 코드는 꽤나 C스럽다..
5. List형 데이터를 반복시킬 때는 이렇게 하는 것이 정석이다.
그러나 여러 컬럼을 for문 내에서 사용할 때는 위 방법이 어렵다.

for item in df[:3]["URL"]:
print(item)
6. 이렇게 배열의 순서를 찾는 것이 안 될 것은 없지만..
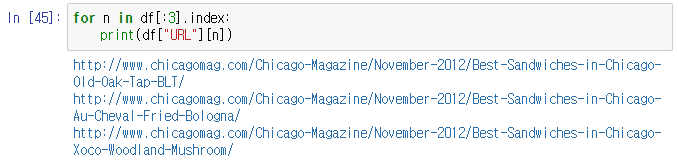
for n in df[:3].index:
print(df["URL"][n])
7. iterrows() 함수를 사용하는 것이 좀 더 좋다.
- 받는 인자로 인덱스와 나머지 row를 받는다는 것에 주의하자.
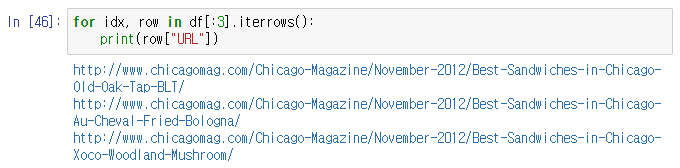
for idx, row in df[:3].iterrows():
print(row["URL"])
8. Okay... 이제 전체로 다 돌려보자.

price = []
address = []
for idx, row in df[:5].iterrows():
req = Request(row["URL"], headers={"user-agent":"Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx)
priceaddress
9. TQDM
- for문을 사용할 때 이게 동작중인지.. 얼마나 시간이 남은건지.. 답답할 때가 많다. 이 때 사용한다.

!pip install tqdm설치하자..

잘 되다가..

말을 안듣는다..^^..
HTTPError Traceback (most recent call last)
Cell In[61], line 8
6 for idx, row in tqdm(df.iterrows()):
7 req = Request(row["URL"], headers={"user-agent":ua.ie})
----> 8 html = urlopen(req).read()
9 soup_tmp = BeautifulSoup(html, "html.parser")
10 gettings = soup_tmp.find("p", "addy").get_text()알 수 없는 이유로.. 시카고 매거진이 이 페이지에서 연결하는 하위 50개 페이지의 주소가 상대주소와 절대주소가 혼용되어 있다^^..
상대주소 절대주소 대응을 위한 명령을 입력한다.

from urllib.parse import urljoin
url_base = "http://www.chicagomag.com"

from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"user-agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx)이제 말을 잘 듣는다^^
10.

len(price), len(address), len(df)
df.head(10)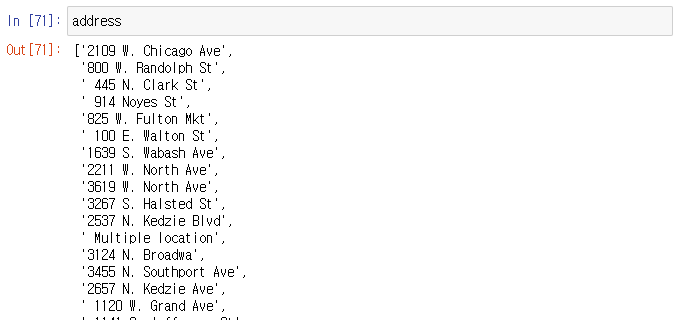
address
price
11. 아주..좋다
이제 저장해주자

df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
df.head()
df.to_csv(
"../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="UTF-8"
)'데이터 분석 > EDA_웹크롤링_파이썬프로그래밍' 카테고리의 다른 글
| [WebData][Movie] 1. 네이버 영화 평점 사이트 분석 (0) | 2023.02.05 |
|---|---|
| [WebData][chicago] 6. 시카고 맛집 데이터 지도 시각화 (0) | 2023.02.05 |
| [WebData][chicago] 4. 하위페이지 분석 (0) | 2023.02.05 |
| [WebData][chicago] 3. 50개 가게에 대해 정보 추출 (0) | 2023.02.05 |
| [WebData][chicago] 2. 접근 태그 확인하기 (0) | 2023.02.05 |



