
RUBY
[WebData][Movie] 2. 자동화를 위한 코드 본문
웹 데이터 수집하고 정리하기
네이버 영화 평점 사이트 분석
2. 자동화를 위한 코드
1. 날짜만 변경하면 원하는 기간 만큼 데이터를 얻을 수 있다.
https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20230205
- pandas의 date_range를 이용하면, 손쉽게 날짜를 만들 수 있다.
- 2022.10.29 부터 오늘날짜까지 100일을 생성한다.

date = pd.date_range("2022.10.29", periods=100, freq="D")
date
2. 날짜형 데이터들은 원하는 형태로 출력이 가능하다.

date[0]date[0].strftime("%Y-%m-%d")date[0].strftime("%Y.%m.%d")
3. 파이썬의 string(문자형) 데이터형은 foramat이라는 재미난 기능이 있다
- {}중괄호로 두고, format 옵션으로 손쉽게 내용을 만들 수 있다.

test_string = "Hi, I'm {name}"
print(test_string.format(name="Jieun"))
print(test_string.format(name="Ruby"))
4. 필요한 모듈을 하나 부르고 얻고 싶은 데이터를 저장할 빈 리스트를 생성한다.

import time
from tqdm import tqdmmovie_date = []
movie_name = []
movie_point = []
5. 이제는 100일간의 데이터를 for문으로 받아오기만하면 된다!
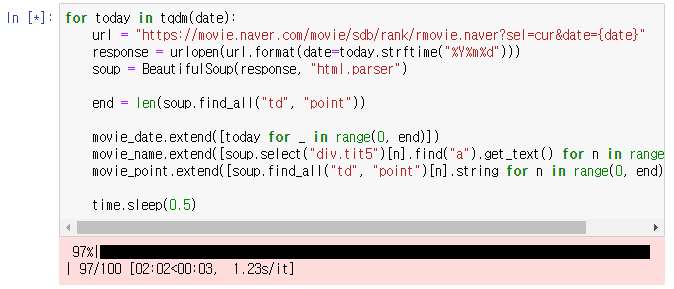
for today in tqdm(date):
url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date={date}"
response = urlopen(url.format(date=today.strftime("%Y%m%d")))
soup = BeautifulSoup(response, "html.parser")
end = len(soup.find_all("td", "point"))
movie_date.extend([today for _ in range(0, end)])
movie_name.extend([soup.select("div.tit5")[n].find("a").get_text() for n in range(0, end)])
movie_point.extend([soup.find_all("td", "point")[n].string for n in range(0, end)])
time.sleep(0.5)
문제 없이 잘 받아왔다.

len(movie_date), len(movie_name), len(movie_point)
6. pandas 데이터 프레임으로 만들자
- 이 데이터는 Raw Data가 된다.

movie = pd.DataFrame({
"date": movie_date,
"name": movie_name,
"point": movie_point
})
movie.tail()
7. 100일치 영화 평점 데이터 정보 확인하기

movie.info()
8. 저장

movie.to_csv(
"../data/03. naver_movie_data.csv", sep=",", encoding="utf-8"
)'데이터 분석 > EDA_웹크롤링_파이썬프로그래밍' 카테고리의 다른 글
| [WebData][Oil] 1. Selenium 설치 (0) | 2023.02.05 |
|---|---|
| [WebData][Movie] 3. 영화 평점 데이터 정리 (0) | 2023.02.05 |
| [WebData][Movie] 1. 네이버 영화 평점 사이트 분석 (0) | 2023.02.05 |
| [WebData][chicago] 6. 시카고 맛집 데이터 지도 시각화 (0) | 2023.02.05 |
| [WebData][chicago] 5. Regular Expression (1) | 2023.02.05 |
'데이터 분석/EDA_웹크롤링_파이썬프로그래밍' Related Articles
more




Comments